Document-Based QC Record Storage with MongoDB and Flask
Manufacturing device history with complete test, calibration, and stateful logging.
10/11/20245 min read
Quality records in hardware manufacturing have an awkward shape. They're not quite tabular — every device type has its own constellation of tests, calibration coefficients, firmware versions, and history events. They're not quite freeform either — auditors want consistent fields, traceability, and the ability to ask "what was the calibration coefficient applied to device 15-03-55-87 on October 22nd" and get a real answer. This post is about MongoQC: a Flask-based REST API in front of a MongoDB document store that I built to mediate every quality record at Resensys, from initial test definition through audit-ready retrieval. It's a story about why documents beat rows for this particular problem, and about the discipline of treating an API as a contract.
Why documents, not rows
The first instinct of most engineers reaching for a database is a relational one. Tables, foreign keys, normalized schemas. I started there too, and pretty quickly hit a wall: every new device type wanted a slightly different schema. A strain gauge has tests a tilt sensor doesn't. A vibration sensor has calibration coefficients across multiple data formats; a simpler device has one. The voltage range that's acceptable for one device type is wrong for another. You can model this in a relational schema — a bunch of join tables and nullable columns — but the result is a schema that mostly describes accidents of history rather than the actual structure of what you're storing.
MongoDB inverted the problem. A device's quality record is a single document. The document has a known shell — device ID, site ID, device type, who prepared it, who approved it — and inside that shell, an array of tests and an array of calibration coefficients that are shaped however that device type needs them to be. New device types don't require schema migrations. Audit queries are still straightforward because the indexed fields are consistent. And when a quality engineer wants the full picture of a device, the picture comes back as one self-contained document rather than a join across six tables.
I want to be careful here: "document database" is not a free pass. The schema flexibility that makes Mongo a good fit is also the rope you can hang yourself with. The discipline that has to come back somewhere is in the API layer, which is exactly where I put it.
The Flask API as the schema enforcer
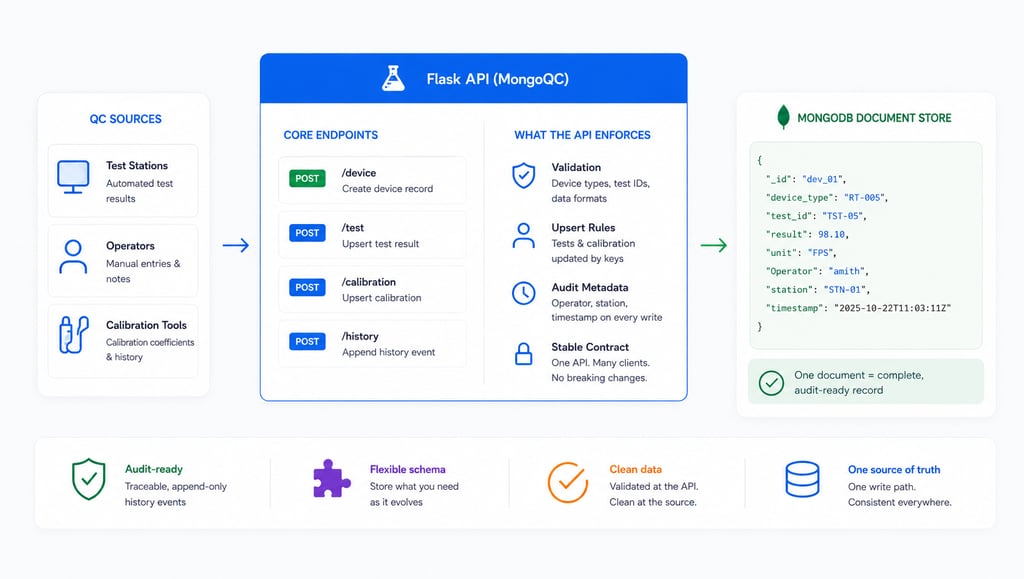
The MongoQC API is a small Flask service sitting between every test station, every operator interface, and the Mongo backing store. Its job is simple to describe and consequential to get right: nothing writes to Mongo without going through the API, and the API enforces the structure of what gets written.
The endpoints group naturally into a few categories. Device endpoints handle the lifecycle of a device record — creation (POST /device, which checks the device type against a controlled list), retrieval (GET /device/<did>), history append (POST /device/<did>/history), test results (POST /device/<did>/test), and calibrations (POST /device/<did>/calibration). Test definition endpoints expose the canonical list of tests so that test stations don't invent their own test IDs (GET /tests, GET /tests/<test_id>). Quantity endpoints handle the small but surprisingly important problem of mapping between human-readable quantity names and the data format integers the firmware actually emits (GET /df_info/<df>, GET /quantity_info/<quantity>).
The two endpoints I'm most fond of are POST /device/<did>/test and POST /device/<did>/calibration, because they encode a key piece of the discipline: they upsert by test ID and by data format respectively. A device's third re-test on test 5 doesn't create a third row; it updates the existing entry. Calibration coefficients for a given quantity replace previous values rather than accumulating noise. That sounds small, but it's the difference between a record that tells you the current state of a device cleanly and a record you have to re-derive every time you read it.
Append-only history, by design
There's one place I deliberately broke the upsert pattern: device history. The history endpoint is append-only. Every history record (a typed event with notes — INFO, REWORK, FAIL, NOTE, and a few others) is added, never modified, never deleted. I made this choice early and I'd make it the same way today.
The reason is auditors and operators. Auditors want a record that cannot be edited after the fact, because a record that can be edited is a record that can be quietly cleaned up before an inspection. Operators want a record that captures what actually happened, including the ugly parts — the device that failed three times before passing, the rework note that explains why a coefficient was changed. If history is editable, both of those uses get worse. Append-only is a small constraint that buys a lot of trust.
The shape of a device document
A device document, as it actually lives in Mongo, has a few core fields: did (device ID), sid (site ID, formatted XX-XX in hex), device_type (validated against the controlled vocabulary), prepared_by, approved_by, an array of coefficients, and an array of tests. Coefficients carry a quantity name, a coefficient and offset, the unit, and a timestamp. Tests carry the equipment used, a description of the procedure, a pass criterion, the result, and a last_modified timestamp.
What's worth noting is what isn't in the document. There's no field for "is this device good to ship?" because that's a derived question — you compute it from whether the required tests for that device type are present and passing. There's no field for the latest cellular signal reading, because that's not a quality record; it lives in the time-series infrastructure on the operations side. The document is deliberately scoped to what quality cares about, and the API enforces that scope.
What the API gives you that direct DB access doesn't
I get asked sometimes why we don't just let test stations talk to Mongo directly. Mongo has authentication, after all, and the network is internal. The answer is that the API is doing several things the database can't:
Validation. The API checks that a device_type is in the controlled list before creating a record. It checks that a test_id maps to a real test definition. It checks that calibration data formats are real data formats. Mongo will happily accept any document you give it; the API ensures the documents you give it are well-formed.
Audit metadata. Every write through the API stamps the request with the operator, the test station, and a timestamp. Auditors want this. Direct database writes lose this context.
Upsert semantics. The API encodes the rules for how a test result or calibration entry replaces a previous one. That logic shouldn't live in every test station's code; it should live in one place that can be tested and changed atomically.
A stable contract. Test stations, operator interfaces, and downstream tooling all talk to the same API. If we ever need to change the underlying storage — and we have, more than once, in smaller ways — the API contract stays put. The cost of change drops dramatically when there's exactly one place to change it.
What I'd do differently
If I were starting MongoQC over today, I'd invest more in input validation libraries from day one. The first version of the API did validation by hand in each endpoint, which is fine until you have [PLACEHOLDER: number of endpoints] endpoints and your validation logic is subtly different in each one. A schema-driven validation layer (Pydantic, marshmallow, or similar) would have saved a lot of paper cuts.
I'd also build the test-definition system with versioning from the start. Tests evolve — a procedure gets refined, a pass criterion tightens. We currently treat tests as if their definition is stable, which is mostly true and occasionally wrong. A versioned test ID would let us distinguish "passed test 5 v1" from "passed test 5 v2" without ambiguity. It's not a hard fix to retrofit, but it's easier to design in than to add later.
The lesson
The thing I'd tell anyone designing a system like this: the API is more important than the database. The choice of Mongo over Postgres mattered, but it mattered less than the choice to put a strict, well-documented API in front of it. The API is what holds the line on data quality. The database is just where the data sleeps.