Short-Term Memory for a Global SHM System of Systems with Redis
Caching and accelerating metadata retrieval for device routing across worldwide infrastructure.
11/18/20246 min read
A structural health monitoring fleet, viewed at the right level of abstraction, is a system of systems. Thousands of sensors. Hundreds of gateways. Dozens of customer deployments. Each device has an identity, a location, a configuration, a current health, and a stream of incoming readings. The relational database that records all of this for posterity is great at being a long-term archive and bad at being a real-time answer to questions like "what's the most recent voltage I saw from device 15-03-55-87?" or "which devices haven't checked in in the last hour?" This post is about the Redis layer I built to be that real-time answer — a short-term memory for the entire fleet — and the surprising side effect of building it: a way to determine a device's type purely from the quantities it reports, which removed an entire category of human error from manufacturing.
The problem: long-term memory is the wrong tool for short-term questions
Before this work, the truth about a device's current state was scattered. The latest voltage was wherever the latest reading happened to land in the time-series store. The current site assignment was in the QC document database. Routing parameters were in firmware-side configuration. "Has this device checked in recently?" was a query that had to scan over time-series data, which is fine occasionally and expensive constantly. "What's the health of every device in the fleet right now?" was effectively unanswerable in any reasonable amount of time.
This is a classic shape: a system that's optimized for long-term storage being asked to answer short-term questions. The fix is not to make the long-term store faster (you'll never win that fight); the fix is to add a short-term store next to it, kept consistent with the long-term store but optimized for being read constantly.
Why Redis
Redis was an obvious fit, but it's worth saying why. The questions we needed to answer were almost all keyed by device ID — give me the latest of X for device Y. Redis's data model (keys mapping to values, hashes, sorted sets, time-bounded keys) is a perfect match for exactly that. The latency budget for these reads was on the order of milliseconds; Redis answers in microseconds. The data we cared about was small — kilobytes per device, not megabytes — so even a fleet of 10,000 devices fits in a single instance with room to spare.
The alternative was to build something custom on top of the existing relational database — materialized views, careful indexing, a memcache layer. We'd done versions of this before, and they always ended up slower and more brittle than they needed to be. Redis is the right tool because it's the tool actually built for this job.
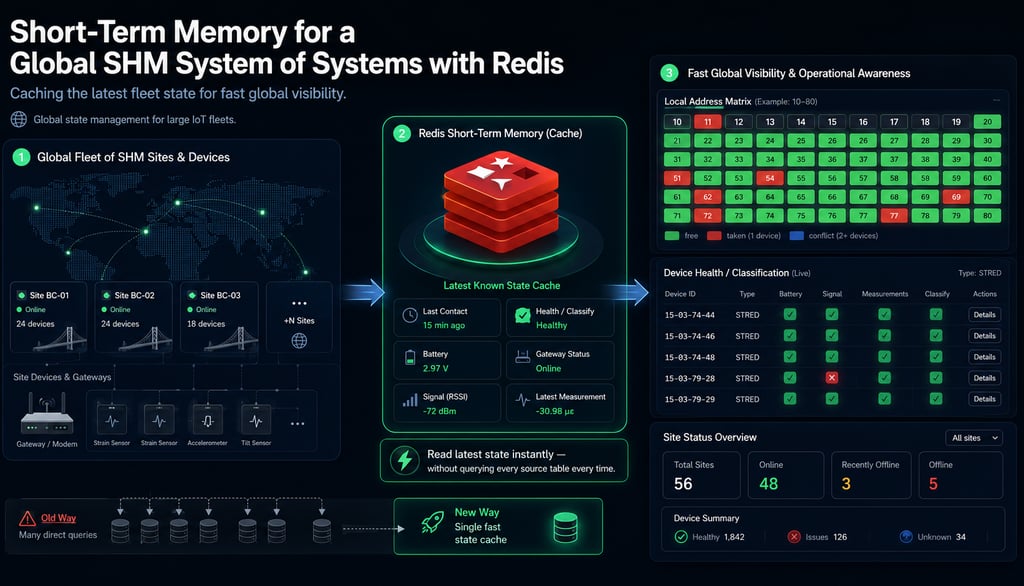
What lives in the cache
The cache holds the last-known state of every device in the fleet. For each device, that means: device type, routing parameters (local addresses, site IDs, gateway associations), the latest reading for each quantity the device reports, the last connection time, and a small set of computed health states — one for voltage, one for RSSI, and one or more device-specific ones (strain reasonable? tilt within range? temperature in spec?). Each piece of data is keyed by device ID and namespaced so a single device's full state is reconstructable in a handful of operations.
Updates flow in two directions. Reads from the field — sensor readings arriving via the gateway — update the relevant cache entries on the way in, before they're persisted to long-term storage. Writes from the manufacturing and provisioning side — a new device registered, a site ID assigned, a calibration applied — push the relevant entries into the cache as the source of truth changes. The pattern is "cache as a derived view, kept fresh by the same code that updates the underlying records," which is the only pattern that doesn't drift over time.
The unexpected win: device-type inference
The thing I'm proudest of from this project came out of the cache almost as a side effect.
Historically, a device's type was set at manufacturing time by a human. Someone selected "RevC Strain Gauge" or "Tilt Sensor SenSpot" or whatever the device was, and that selection became part of the device's record. This worked, but it was fragile. People mistype. People copy and paste from the wrong row. People are working at three in the afternoon on a Thursday and the device that should have been a tilt sensor gets registered as a strain gauge, and that error doesn't get caught until the device is in the field reporting quantities its declared type doesn't support.
Once the cache was in place and the latest reading for each quantity per device was always one lookup away, a different approach became possible: don't ask a human what kind of device this is — ask the device. A strain gauge reports strain. A tilt sensor reports angles. A vibration sensor reports acceleration spectra. The set of quantities a device actually reports is, in practice, a near-perfect signature of what kind of device it is. I built a small inference layer on top of the cache: as soon as a device has reported its first few minutes of data, the system can determine its device type by looking at which quantities are present in the cache for that device, with confidence high enough to use in production.
This sounds like a small thing. It is not a small thing. It eliminated an entire class of human error from manufacturing. It removed a step from the device registration process. It made it possible to bulk-initialize devices in the QC system and let the system sort itself out as the devices started reporting, rather than requiring a human to label each one. The previous workflow had a 20-25% rate of device-type misregistration that we caught later through various downstream checks; the new workflow has approximately none, because there's no human in the loop to make the mistake.
Bulk initialization and a global state
Once you have a cache that reflects the live state of every device, and once you have a way to determine device types automatically from reported quantities, a few things become possible that weren't before.
Bulk initialization is the obvious one. A new manufacturing run produces, say, fifty devices. Previously, each one needed a human-driven registration step before it could be tracked. Now, the QC system can register all fifty as soon as they're powered on and reporting; the cache picks up their first readings, the inference layer assigns device types, and downstream systems treat them as fully provisioned. The throughput change here is meaningful — see the post on the QC Cloud Platform for what we did with that headroom.
Less obvious is what the cache enables at the global level. With the live state of every device sitting in one place, queryable in milliseconds, you can ask questions about the fleet as a whole that previously required batch jobs. "How many devices have low battery right now?" "Which deployments have a connectivity issue in the last hour?" "What's the distribution of RSSI across the fleet by region?" These are the kinds of questions that turn an SHM company from one that monitors individual structures to one that has visibility into a continental sensor network.
For more details about the global Resensys fleet, you can see the short-term memory layer in action by visiting https://status.resensys.cloud/. Literally billions of SQL queries can now be condensed to a handful of in-memory database transactions to show the status of thousands of devices.
Stateful production: a quiet implication
There's a broader idea hiding in this work that I'll only sketch here. Most consumer electronics manufacturing is implicitly stateless: you assemble a unit, you ship it, the manufacturing system forgets about it, and the unit lives the rest of its life as someone else's problem. SHM devices live differently — they stay in the system after they ship, because the system needs to keep monitoring them. Once the cache exists and the global state is real, the manufacturing system and the field system aren't two separate things; they're two phases of the same continuous process.
I believe — and this is the one place I'll allow myself a small claim — that this pattern, of treating production as a continuous stateful process rather than a batch handoff, is something that more U.S. manufacturers will move toward as the tools get easier. Redis, Mongo, Flask, Streamlit: nothing here is exotic. The barrier was never the technology. It was the design choice to treat the fleet as a single system with short-term memory, rather than a pile of devices that the database catalogs after the fact.
What I'd do differently
I'd build the inference layer's confidence scoring more deliberately from the start. The current version is good enough — it's correct in essentially every case we've seen — but the way it expresses confidence is implicit, not numeric. A device with one minute of data and a device with one hour of data are both "determined" the same way; they shouldn't be. A version that returned a probability over device types, with a configurable confidence threshold for promotion to "determined," would be more honest about what the system actually knows when.
I'd also commit earlier to durable persistence settings on the Redis side. Treating the cache as fully derivable from the source of truth was the right model, but the cost of rebuilding it after a Redis restart was higher than I expected. RDB snapshots and AOF would have made that less painful.
The takeaway
Adding short-term memory to a system that previously only had long-term memory is one of those changes that sounds incremental and turns out to be transformative. The cache made the questions we already asked faster. It also made entirely new categories of question feasible — device-type inference, fleet-level state, bulk initialization. The lesson, generalized: when a system can't answer a question fast enough to be useful, the answer is almost never "make the existing storage faster." The answer is "add the right kind of memory next to it."